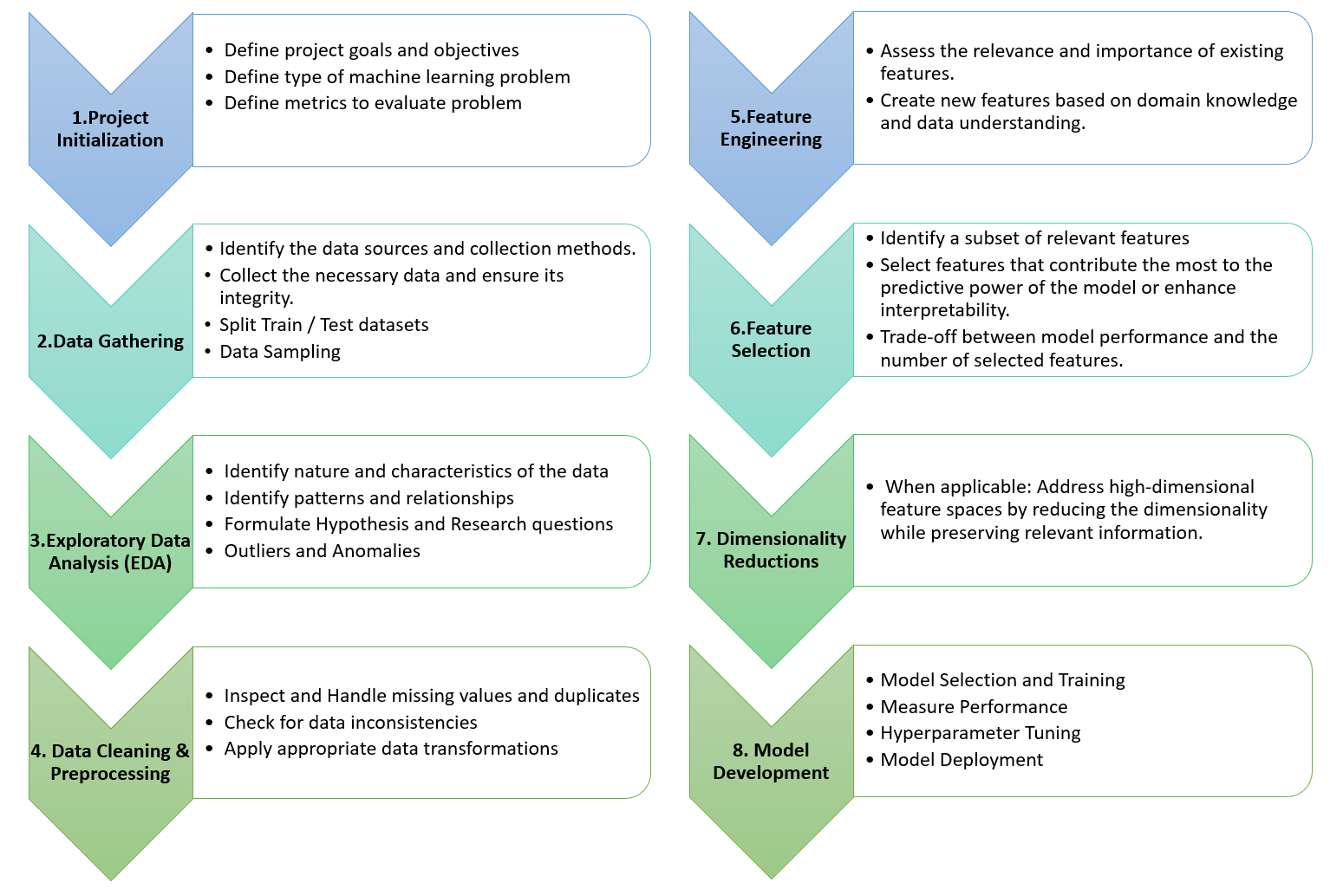
Process Structuring: One of the biggest challenges was understanding and sequencing the steps in a data science project. Overcoming this helped create a reusable framework for future projects.
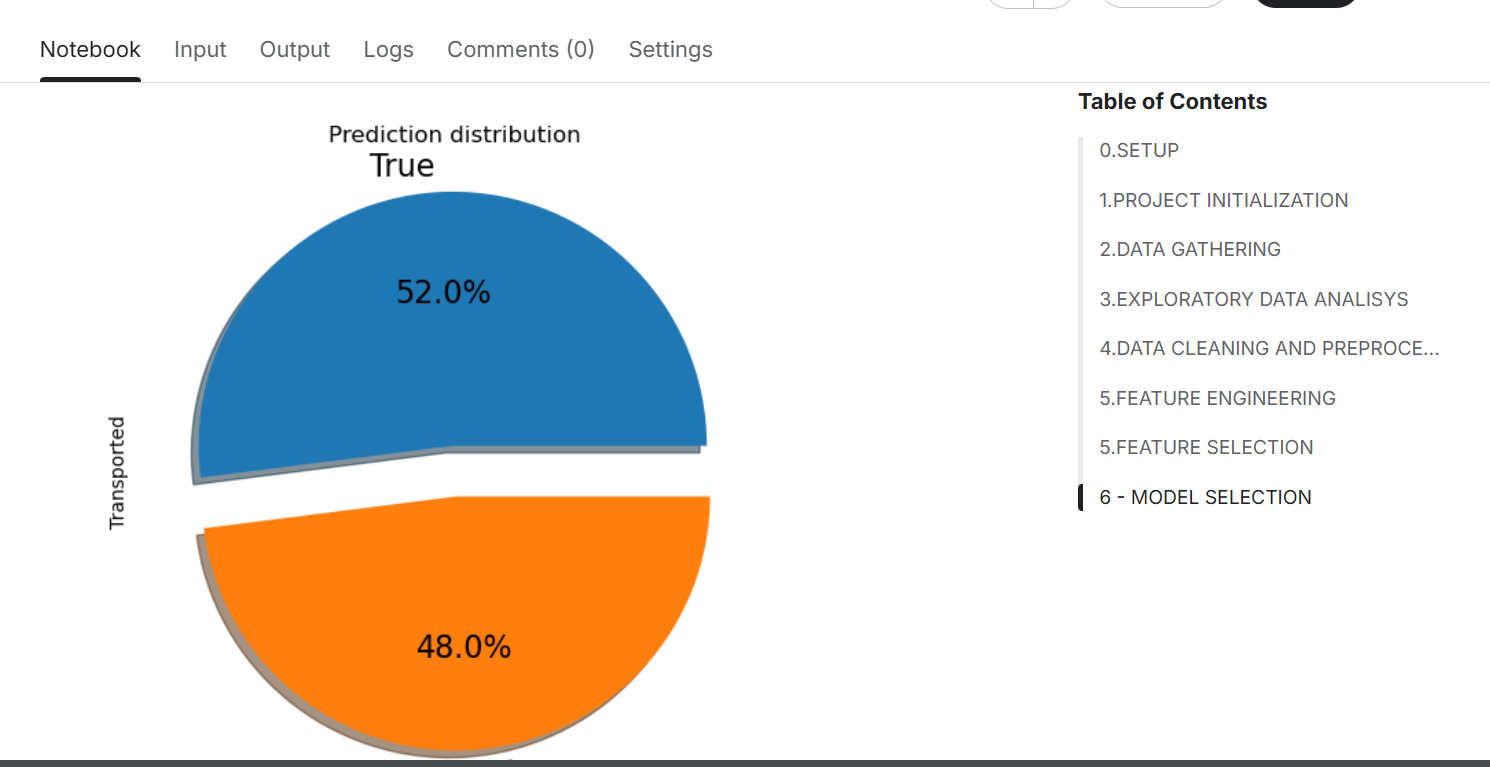
Feature Engineering: Identifying meaningful features in a fictional dataset required creativity, experimentation, and iteration.
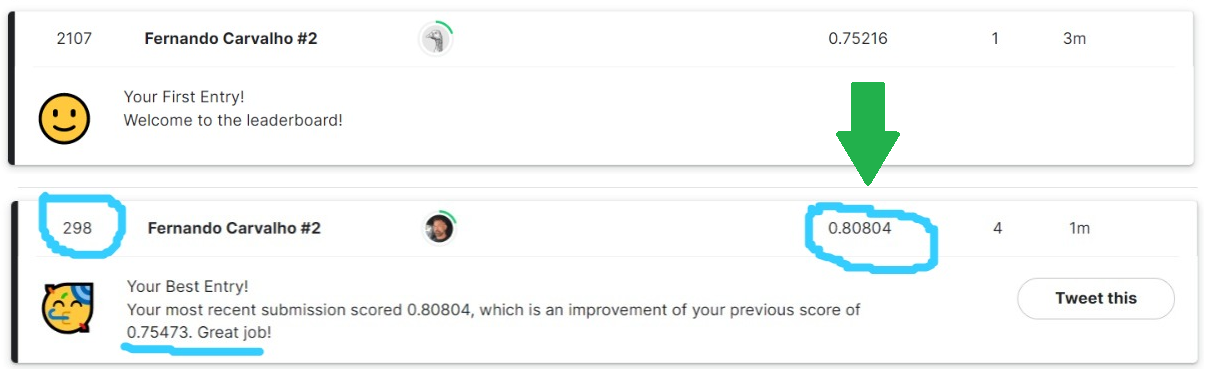
Model Optimization: Learning how to fine-tune models and evaluate performance using cross-validation techniques was a key technical milestone.
Self-Guided Learning Discipline: Without formal guidance, managing resources (YouTube, books, ChatGPT, etc.) and adapting to unexpected problems was an exercise in self-reliance and growth.
Critical Thinking & Domain Understanding: Practiced translating vague problem definitions into measurable modeling objectives—a key data science skill.